
You know what’s funny? I’ve been coding for years, and somehow I never realized how ridiculously easy it’s become to convert text into decent-sounding speech. Like, we’re talking about transforming your boring documentation into podcast-quality audio with just a few terminal commands.
Seriously, when did this happen? Last time I checked—probably around 2022—TTS was this painful experience where “Hello World” came out sounding like Stephen Hawking’s computer having technical difficulties. But Microsoft’s Edge TTS? It’s genuinely good. Like, “wait, is this actually synthetic?” good.
The crazy part is how stupidly simple it’s become. We’re talking about transforming your dry technical docs into something people might actually want to listen.
Getting Started: The Two-Minute Setup
Let’s be honest—most tutorials assume you’re starting from a pristine development environment. Reality check: your machine probably has three different Python versions, some broken pip installations, and that one package you installed six months ago that’s now causing mysterious conflicts.
Checking Your Python Installation
Fire up PowerShell (or whatever terminal doesn’t make you want to throw things):
- Press the Win key
- Type “PowerShell”
- Hit Enter
Now check if Python’s ready to go:
python --versionYou might get Python 3.11.4 or maybe Python 3.9.7—honestly, anything 3.7+ works fine. If you get a “command not found” error, well… we’ve all been there.
python -VHere’s something nobody tells you: if you’re on Windows and Python opens the Microsoft Store instead of showing a version, that’s actually normal now. Microsoft decided to be “helpful” by redirecting the python command. Just grab Python from python.org like the rest of us mortals.

If you get an error instead, head over to python.org and grab the latest version. The installation is straightforward—just follow the prompts.
🎯 Pro Tip from Years of Pain
pip doesn't work.Here’s the thing about Python installations: they’re usually painless these days, but if you run into PATH issues (and we’ve all been there), just make sure to check the “Add Python to PATH” box during installation.
Installing Edge-TTS
This is where things get refreshingly straightforward:
pip install edge-tts
That’s it. Seriously. The installation is surprisingly quick and clean—no complicated dependencies, no version conflicts, just a simple package that works.
Choosing Your Voice: More Options Than You’d Expect
Before we start converting text, you’ll want to see what voices are available. Trust me, the selection is impressive:
edge-tts --list-voices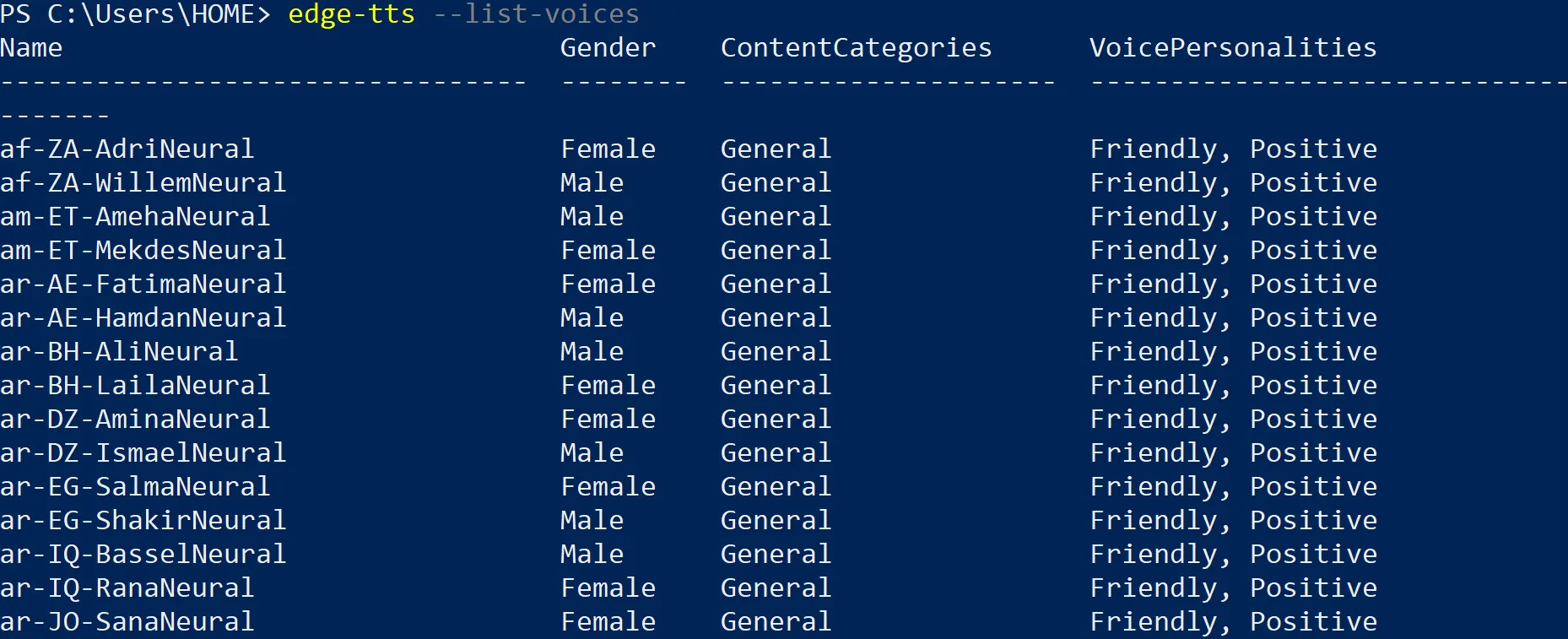
This command spits out a massive list—we’re talking dozens of voices across multiple languages. You’ve got neural voices (the good stuff) that sound remarkably human, and they range from professional newsreader tones to more conversational styles.
Some popular English options include:
en-US-AriaNeural- Clear, professional female voiceen-US-JennyNeural- Warm, friendly female voiceen-US-GuyNeural- Natural-sounding male voiceen-US-DavisNeural- Deeper male voice, great for narration
The Basic Command: Your First Conversion
Here’s where the magic happens. Navigate to the folder containing your text file (pro tip: just type cmd in your Windows Explorer address bar), then run:
edge-tts -v "en-US-AriaNeural" -f yourTextFile.txt --write-media yourAudioFile.mp3Let me break this down because understanding each piece makes you way more effective:
edge-tts- The main command that fires up Microsoft’s TTS engine-v "en-US-AriaNeural"- Your voice selection (swap this for any voice from the list)-f yourTextFile.txt- Points to your input text file--write-media yourAudioFile.mp3- Where to save the resulting audio
Real Example in Action
Let’s say you have a file called script.txt with your content. Your command becomes:
edge-tts -v "en-US-AriaNeural" -f script.txt --write-media output.mp3🪄 The Magic Moment
Direct Text Input: Skip the File Creation
Sometimes you just want to test a quick phrase without creating a file:
edge-tts --voice "en-US-JennyNeural" --text "Hello, this is a test of the text-to-speech system." --write-media test.mp3Perfect for experimenting with different voices or testing short snippets. I use this constantly when I’m trying to figure out which voice works best for a particular project.
🔊 Listen: Direct text input command text
Fine-Tuning: Speed and Pace Control
Here’s where you can get creative. Different content needs different pacing—technical documentation might benefit from a slower pace, while casual content can handle a quicker tempo.
Speed It Up
edge-tts --voice "en-US-JennyNeural" --rate="+20%" --text "Your text here" --write-media fast-output.mp3🔊 Listen: Speed adjustment command
Slow It Down
edge-tts --voice "en-US-GuyNeural" --rate="-15%" --text-file article.txt --write-media slow-output.mp3🔊 Listen: Slower pace command
The rate adjustment is surprisingly effective. I’ve found that +10% to +20% works well for most content, while -10% to -15% is perfect when you need clarity over speed.
⚡ Sweet Spot for Speed
Voice Comparison: Finding Your Audio Personality
This is where it gets interesting. Different voices excel at different content types, and honestly, the differences are more pronounced than you’d expect.
Jenny Neural has this warm, conversational quality that works great for tutorials and explanations. Aria Neural sounds more professional—perfect for business content or presentations. Guy Neural brings authority to technical deep-dives.
Here’s what I do: pick a representative paragraph from your content and test it with 3-4 different voices. Takes an extra few minutes but saves you from regretting your choice halfway through a 30-minute audio file.
Aria Neural Sample
🎭 Aria Neural: How to cook pasta
Jenny Neural Sample
🎭 Jenny Neural: Introduction sample
Guy Neural Sample (Male voice)
🎭 Guy Neural: Technical instruction sample
Real-World Workflow: My Process
After months of using this tool, here’s my go-to workflow:
Step 1: Clean Your Text
If you’re working with Markdown or formatted text, strip out the formatting first:
sed 's/[#*`]//g' article.md > clean-article.txtThis removes common Markdown characters that sound weird when spoken.
Step 2: Test with a Sample
Pick a representative paragraph and test it with your chosen voice:
edge-tts --voice "en-US-JennyNeural" --rate="+10%" --text "Sample paragraph here" --write-media test-sample.mp3📝 Text Cleaning Process
Step 3: Full Conversion
Once you’re happy with the settings:
edge-tts --voice "en-US-JennyNeural" --rate="+10%" --text-file clean-article.txt --write-media final-audio.mp3🎯 Final Conversion Command
Batch Processing: When You Need Scale
If you’re dealing with multiple files (documentation, blog posts, whatever), bash scripting saves the day:
for file in *.txt; do
edge-tts --voice "en-US-JennyNeural" --text-file "$file" --write-media "${file%.txt}.mp3"
doneThis processes every .txt file in your directory and creates corresponding MP3 files. It’s the kind of automation that makes you feel like you’re living in the future.
Quick Troubleshooting
Command not found? Make sure Python’s in your PATH and you’ve installed edge-tts properly.
Weird audio artifacts? Try a different voice—some handle certain text patterns better than others.
File not found errors? Double-check your file paths and make sure you’re running the command from the right directory.
Audio sounds robotic? You might be using a non-neural voice. Stick with the “Neural” voices for the most natural results.
That’s pretty much it. You now have the knowledge to turn any text into professional-sounding audio with just a few commands. Go forth and make your content more accessible, more engaging, and honestly, just more cool.
The next time someone asks how you created that smooth voiceover for your project demo, you can just smile and say, “Oh, that? Just a little Python magic.”
Stay up to date
Get notified when I publish something new, and unsubscribe at any time.